
Protocol buffers provide a language-neutral, platform-neutral, extensible mechanism for serializing structured data in a forward-compatible and backward-compatible way.
Protocol buffers are a combination of the definition language (created in
.protofiles), the code that the proto compiler generates to interface with data, language-specific runtime libraries, and the serialization format for data that is written to a file (or sent across a network connection).
Overview
Cross-project Support
Use protocol buffers across projects by defining message types in .proto files that reside outside of specific project’s code base.
If define message types or enums, it means this might be widely used outside of immediate team. Which can put them in own file with no dependencies.
ex:
message Timestamp {
int64 seconds = 1;
int32 nanos = 2;
}
Updating Proto Definition Without Updating Code
- When update
.protodefinitions, old code will read new messages without issues, it ignore any newly added fields. - To old code, fields that were deleted will have their default value, and deleted “repeated” fields will be empty
- New code will transparently read old messages
Not good fit case
- data exceeds a few megabytes ( larger data) ==> might cause spike
- Protocol buffer assume entire message can be loaded into memory at once, and not larger than an object graph.
- Need to fully parsing 2 message to compare equality between them. When protocol buffer are serialized, same data can have many different binary serializations
- message not compressed
- special-purpose compression algorithms like the ones used by JPEG and PNG will produce much smaller files for data of the appropriate type
- Protocol buffer messages are less than maximally efficient in both size and speed for many scientific and engineering uses that
involve large, multi-dimensional arrays of floating point numbers.- for these,
FITSand smaller formats have less overhead
- for these,
- non-object-oriented languages popular in scientific computing, ex: Fortran and IDL
- don’t inherently self-describe their data
- cannot fully interpret one without access to its corresponding
.protofile
- cannot fully interpret one without access to its corresponding
- not standard
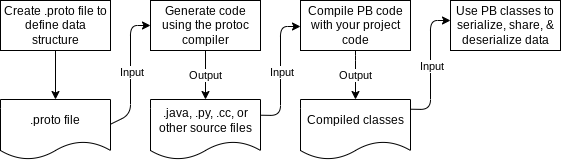
How do Protocol Buffers Work
Language Guide (proto3)
Define a Message Type
- Require
syntax = "proto3";to specify usingproto3syntax. - each field in message definition has a
unique number.Field Numberused to identify fields in message binary format.- Filed Number in
1 - 15take one byte to encode- use it for very frequently occurring message elements
- Filed Number in
16 - 2047take 2 bytes - range from
1 ~ 2^29-1(536,870,911) - Cannot use number through
19000 - 19999which is (FieldDescriptor::kFirstReservedNumberthroughFieldDescriptor::kLastReservedNumber) - Cannot use any previously reserved field numbers
- Field Rules
singular: well-formed message can have 0 or 1 of this field.- default filed rule for proto3 syntax
repeated: repeated any number of times(including 0) in a well-formed message. The order of the repeated values will be preserved- by default, repeated fields of scalar numeric types use
packedencoding
- by default, repeated fields of scalar numeric types use
- Reserved Fields
- if define deleted fields as
reserved, in the future, if other users reuse the field, protocol buffer will complain -
If you update a message type by entirely removing a field, or commenting it out, future users can reuse the field number when making their own updates to the type. This can cause severe issues if they later load old versions of the same .proto, including data corruption, privacy bugs, and so on
- if define deleted fields as
Scalar Value Types
https://developers.google.com/protocol-buffers/docs/proto3#scalar
Default Values of Singulars
- string: empty string
- bytes: empty bytes
- boos: false
- numeric: zero
- enums: first defined enum value, which must be 0
- message: field not set
NOTE:
- for
scalarmessage fields, once message is passed, there isno way of telling whether fields was explicitly set to the default or just not set at all
Enumerations
- every
enumdefinition must contain a constant that maps tozeroas its first element- There must be a
zerovalue, so that use 0 as numeric default value - 0 value needs to be the first element, for compatibility with the proto2 semantics where the first enum value is always the default
- There must be a
- could define aliases by assigning same value to different enum constants.
- set
allow_aliasoption totrue, otherwise the protocol compiler will generate error message when aliases are found
- set
- constants must be in range of 32-bit integer
- because enum values use varint encoding on the wire, negative values are inefficient
- can define enums within a message definition or outside(can be reused)
- can use
enumdeclared in one message as type of fields in a different message, using syntax_MessageType_._EnumType_ - use
reservedto avoid future reuse when delete one fields``
Using Other Message Types
- can use other message Types as fields of another message
- import definitions by
import xxx/xxx.proto; import publichelp forward all imports to a new location
// new.proto
// All definitions are moved here
// old.proto
// This is the proto that all clients are importing.
import public "new.proto";
import "other.proto";
// client.proto
import "old.proto";
// You use definitions from old.proto and new.proto, but not other.proto
Nested Types
- could define and use message types inside other message types
- could reuse message type outside the parent message type by
_Parent_._Type_ - could nest as deeply as we want
Updating A Message TYpe
- don’t change filed numbers for any existing fields
- add new fields
- old message format can still be passed, by using default value for new field
- new message can still be passed into old code, by ignoring new field
- remove fields
- as long as filed numbers is not used again.
- one method is rename field, perhaps by adding
OBSOLETE_ - or make field number
reserved
- one method is rename field, perhaps by adding
- as long as filed numbers is not used again.
int32,uint32,int64,uint64,boolare compatible- could change a field from one of these types to another, without breaking forwards or backwards compatibility
sint32andsint64are compatible with each other but are not compatible with the other integer types.stringandbytesare compatible as long as the bytes are valid UTF-8.- Embedded messages are compatible with
bytesif the bytes contain an encoded version of the message. fixed32is compatible withsfixed32, andfixed64withsfixed64.- For
string,bytes, and message fields,optionalis compatible withrepeated enumis compatible withint32,uint32,int64, anduint64in terms of wire format- change single value into a member of a new
oneofis safe and binary compatible.- move multiple fields into a new
oneofmay be safe if no code sets more than one at a time - move any fields into existing
oneofis not safe
- move multiple fields into a new
Unknown Fields
- unknown fields represent fields that the parser does not recognize
- ex: when old binary parse data sent by new binary with new fields, those new fields become unknown fields in old binary
- proto3 always discard unknown fields during parsing
- in version 3.5 and later, unknown fields are retained during parsing and included in serialized output
Any
Anylets us use messages as embedded types without having their .proto definition- to use
google.protobuf.Any, need toimport "google/protobuf/any.proto";
Oneof
- set
oneoffield will automatically clear all other members of the oneof- if we set several oneof fields, only
lastfield will still have a value
- if we set several oneof fields, only
- a oneof cannot be
repeated - reflection APIs work for oneof fields
- when add or remove oneof fields
- be careful
- if checking the value of a oneof returns
None/NOT_SET, it could mean that oneof has not been set to a field in a different version of the oneof - no way to tell difference
Tag reuse rules
- Move fields into or out of a oneof
- may lose some of information (some fields will be cleared) after message is serialized and parsed.
- can safely move a single field into a new oneof and maybe able to move multiple fileds if itis known that only one is ever set
- Delete a oneof fields and add it back
- may clear current set oneof field after the message is serialized and parsed
- Split or merge oneof
- similar issue with moving regular fields
Maps
- syntax:
map<key_type, value_type> map_field N;key_typecan be integral or string type- enum is
NOTvalidkey_type value_typecan be any type except another map
- map fields
cannotberepeated - When generating text format for a
.proto, maps are sorted by key. Numeric keys are sorted numerically. - When parsing from the wire or when merging, if there are duplicate map keys the last key seen is used.
- When parsing a map from text format, parsing may fail if there are duplicate keys.
- Backwards compatibility
- The map syntax is equivalent to the following on the wire, so protocol buffers implementations that do not support maps can still handle your data
message MapFieldEntry {
key_type key = 1;
value_type value = 2;
}
repeated MapFieldEntry map_field = N;
Packages
- add optional
packagespecifier to a.protofile to prevent name clashes between protocol message types
package foo.bar;
message Open { ... }
message Foo {
...
foo.bar.Open open = 1;
...
}
Defining Services
- syntax
rpcto define an rpc interface if want to use RPC(remote procedure call) system - most straightforward RPC system is gRPC
JSON Mapping
https://developers.google.com/protocol-buffers/docs/proto3#json
Generating Your Classes
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR --go_out=DST_DIR --ruby_out=DST_DIR --objc_out=DST_DIR --csharp_out=DST_DIR path/to/file.proto
- in generate, set
--proto_pathflag to the root of project and use fully qualified names for all imports
Comments
Join the discussion for this article at here . Our comments is using Github Issues. All of posted comments will display at this page instantly.