
Since WWDC 2018, Apple introduces the Vision Framework.
And I’d like to take some nots on it.
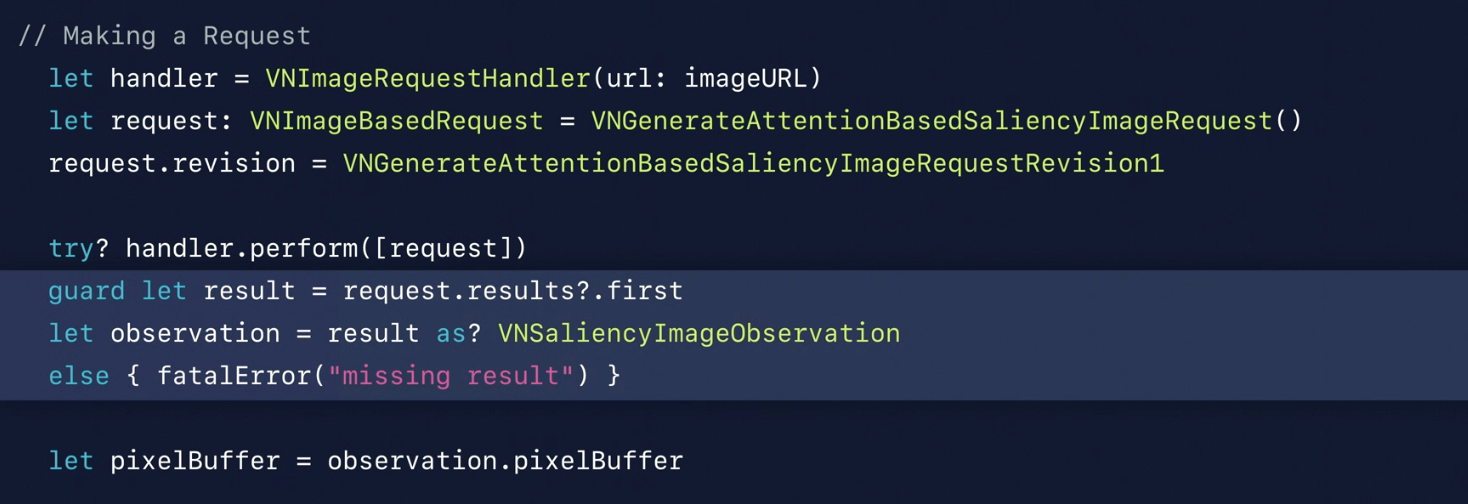
Saliency
Saliency generated people’s attension & objectness. Highlight when people watch the image.
Attention Based
- Human Aspected
- Trained on eye movements
Objectness Based
- Foreground Objects
- Trained on object segmentation
Here is an example image:
- The first picture is the original picture
- The second is attention based picture
- The third is objectness based picture

Determined by
- Contrast
- Faces
- Subjects
- Horizons
- Light
Heatmap
Use
VNGenerateAttensionBasedSaliencyImageRequestVNGenerateObjectnessBasedSaliencyImageRequest
to generate the image with the highlight picture. The highlight part is covered by a heatmap, which point out the Saliency part.
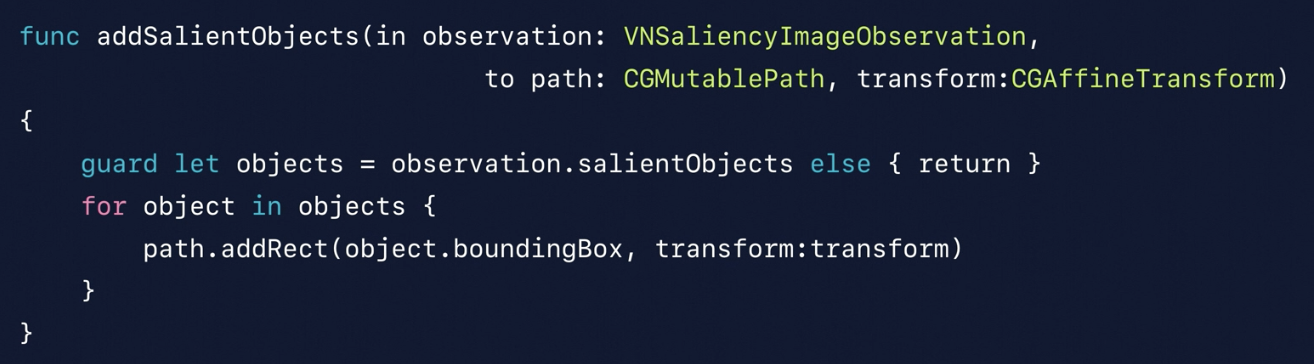
Bounding Box
For attension of the saliency, we will have a bounding box, which could draw out the correct image area.
Here is an example code about how to adding th bounding box and showing it.
Graphical Uses
Add type of filter or photo transition.

Image Classification
- Use saliency to detect the object & return the bounding box-es
- For each bounding box, use image classification to find out which object it is.
Taxonomy
Hierarchical structure, containing around 100 classes. Grouping based on shared semantic meanings. Define relationships between classes of increasing specificity.
Taxonomy Construction
Include classes that are visually identifiable
Avoid
- Abstract /controversial concepts
- Proper nouns, adjectives, and basic shapes
- Occupations
Here is the result of classify image
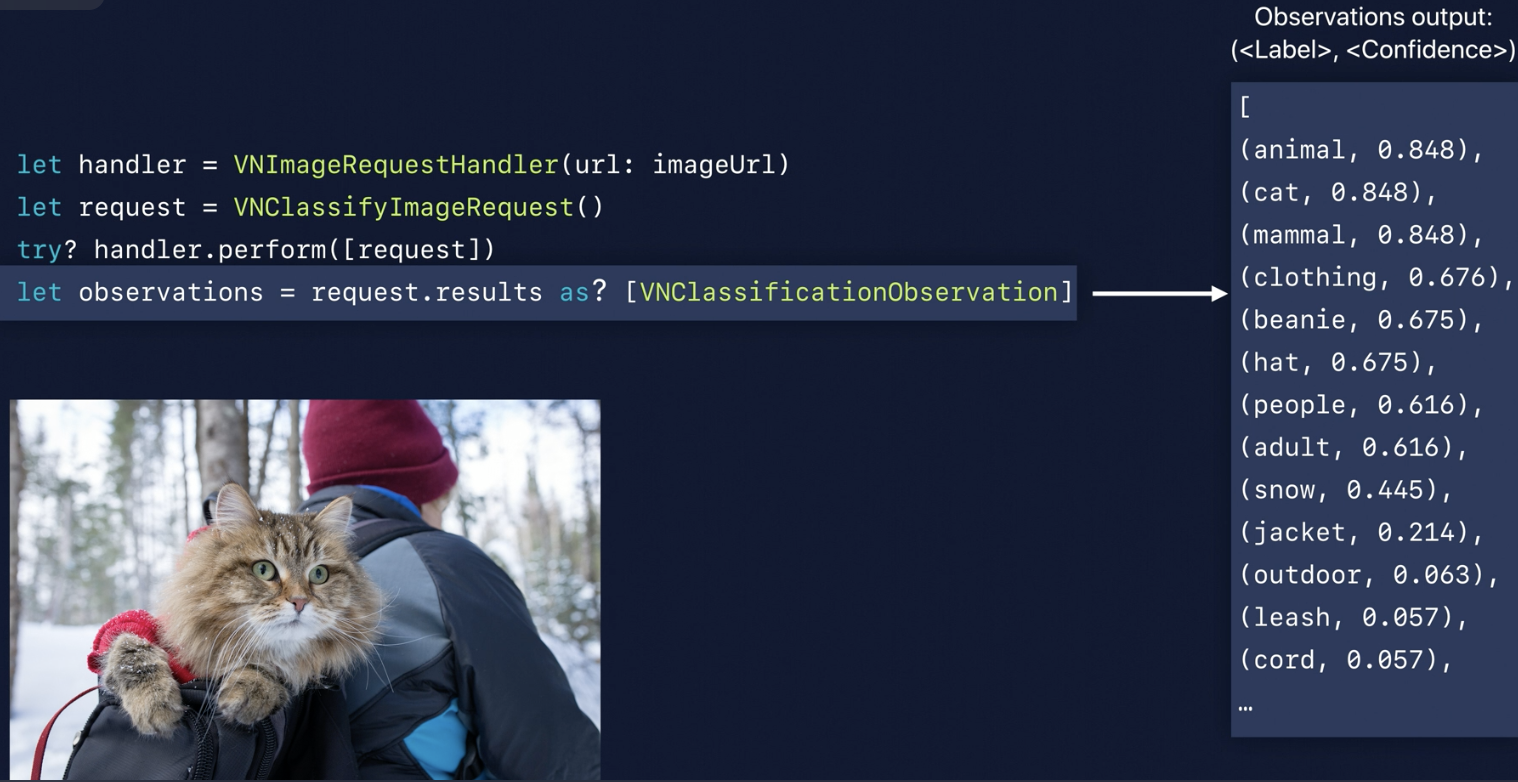
Terms Confidence > Threshold => Predicted image
- Precision and Recall
Add hasMinimumPrecision & Recall params to help filtering the high precision images.
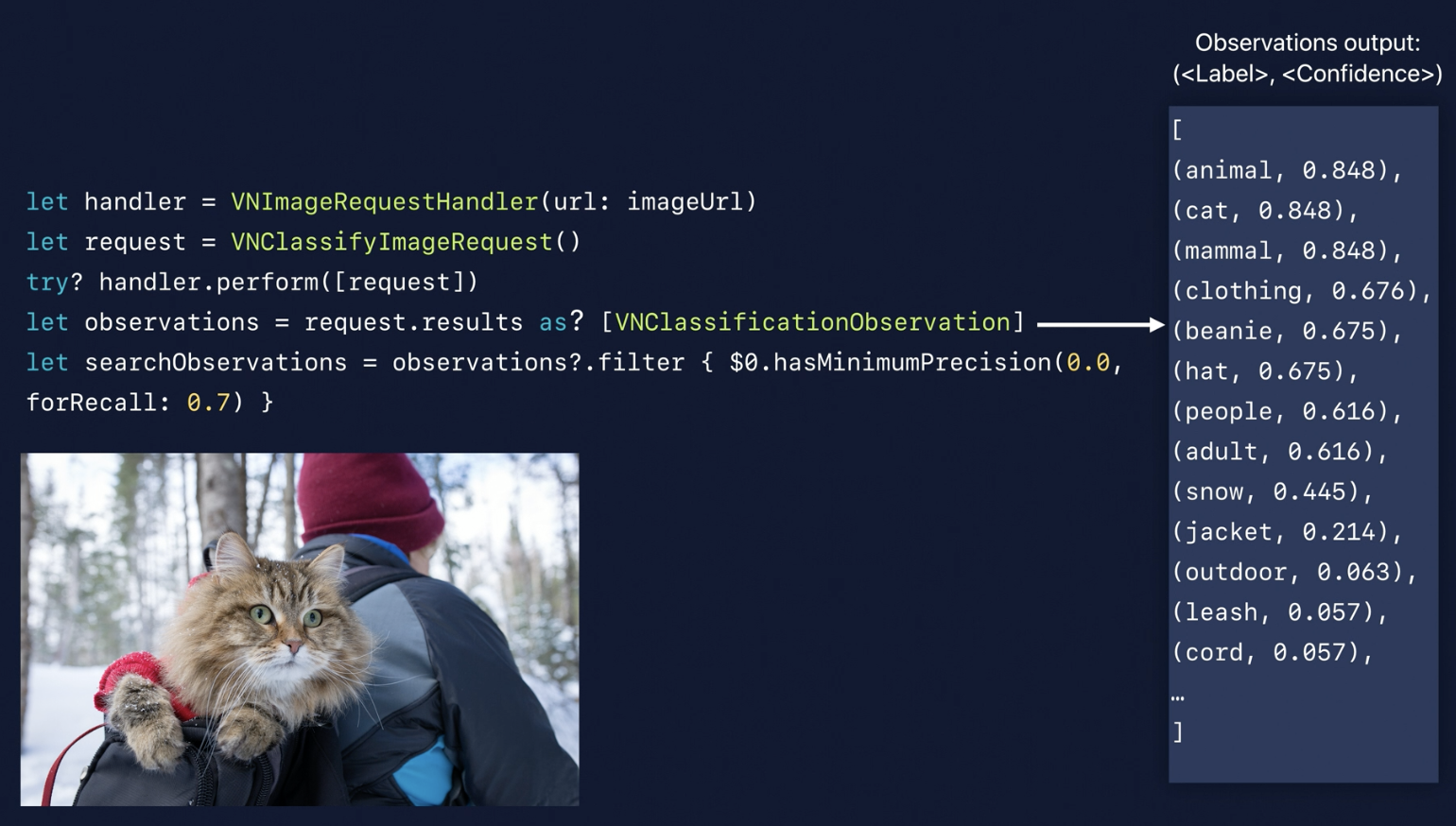
- PR Curve
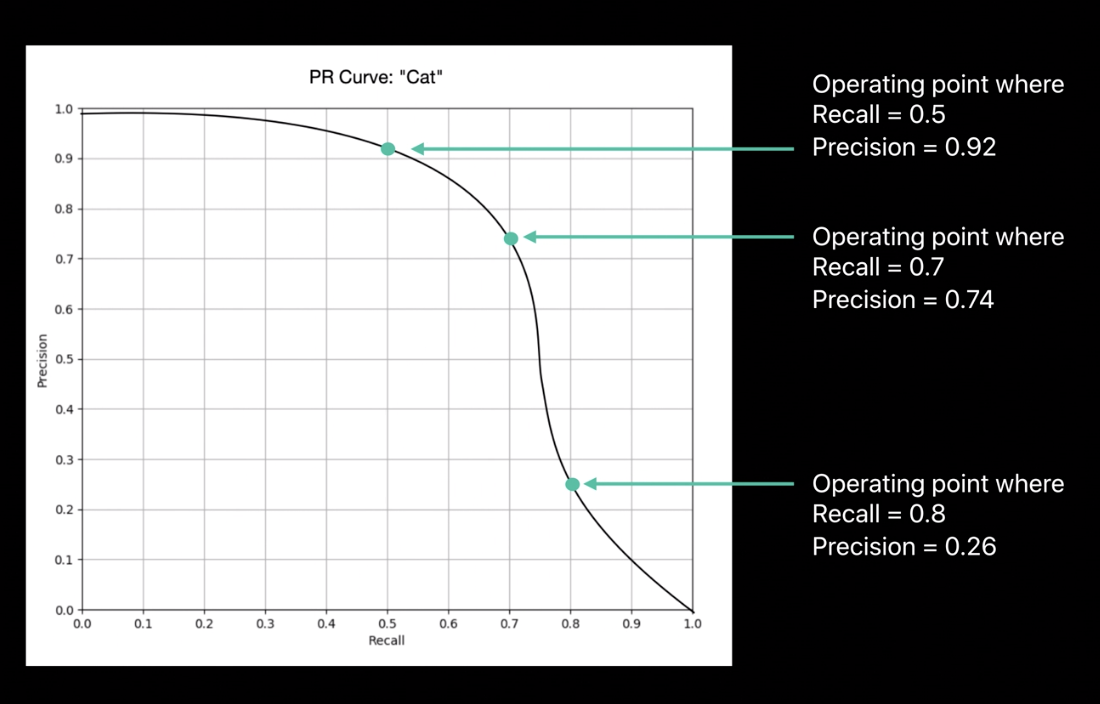
- Use Recall & Precision to controll get the high precision
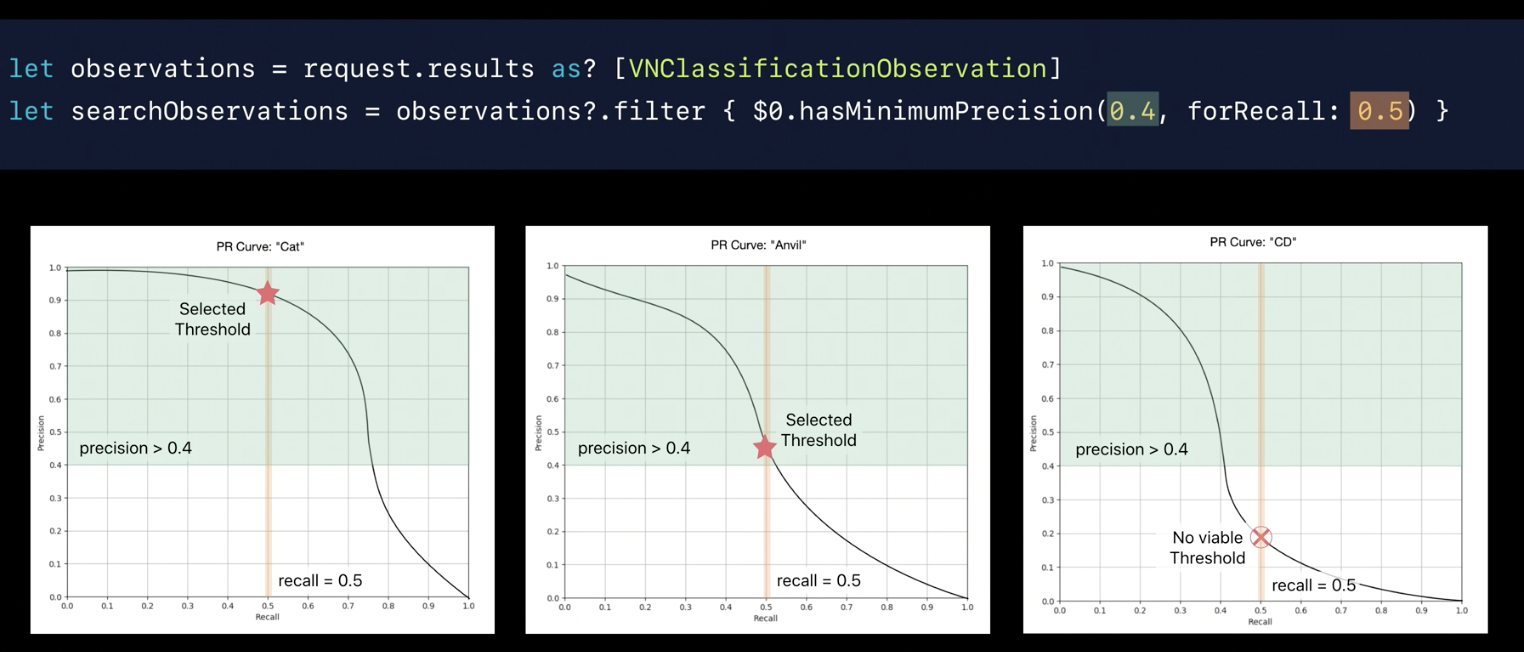
Summary
Returned observation contains labels and an associated confidence. Choice of threshold is application specific. Can be determined by desired precision and recall.
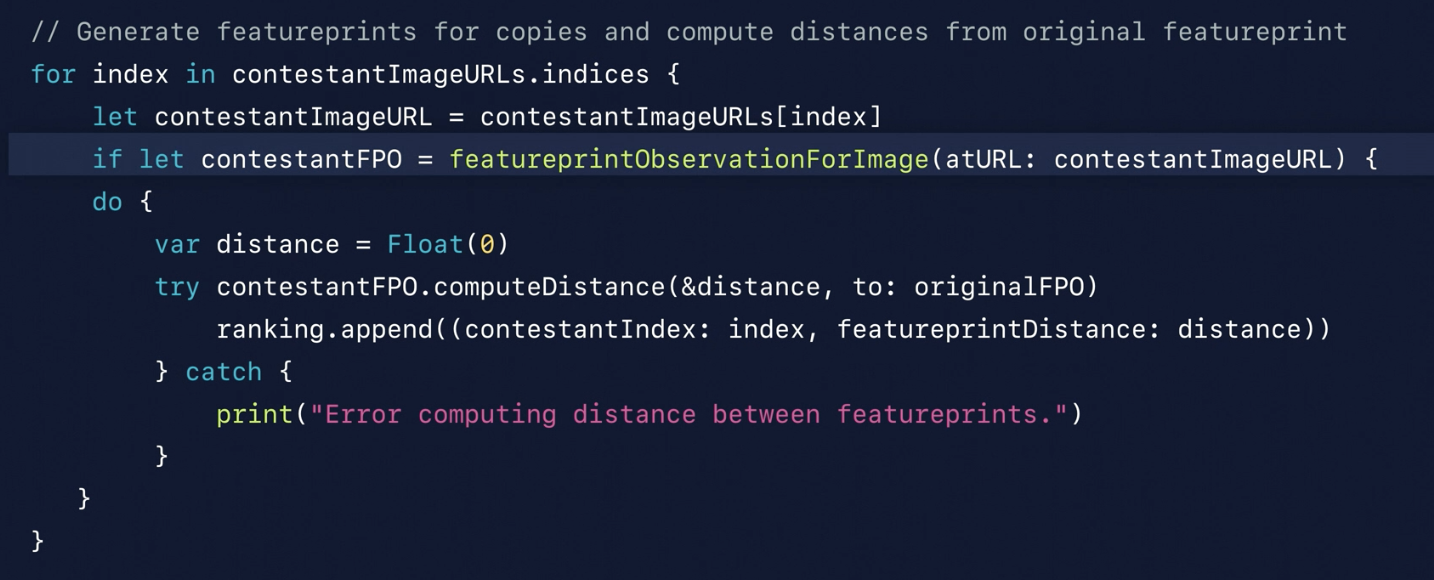
Image Similarity

Descriptor should describes image content, not just appearance. Classification network creates representations of images. FeaturePrint - vector image descriptor similar to a word vector.
Demo
Face Technology
Face Landmarks

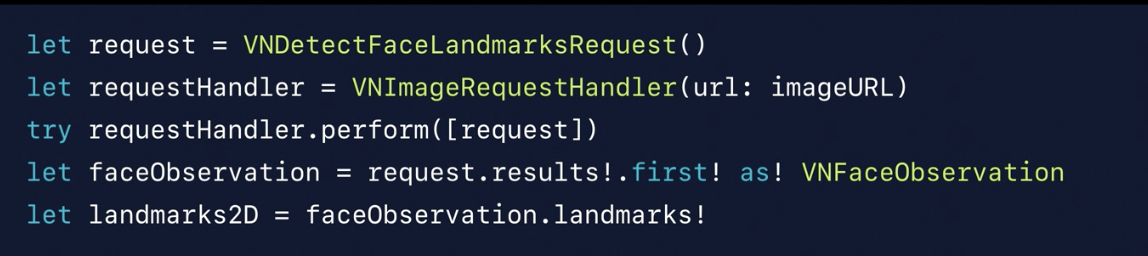
VNDetectedObjectObservation contain bounding Box -> VNFaceObservation(landmarks)
VNFaceLandmarks confidence -> VNFaceLandmarks2D (eyes…)
Revision Example – default versus explicit
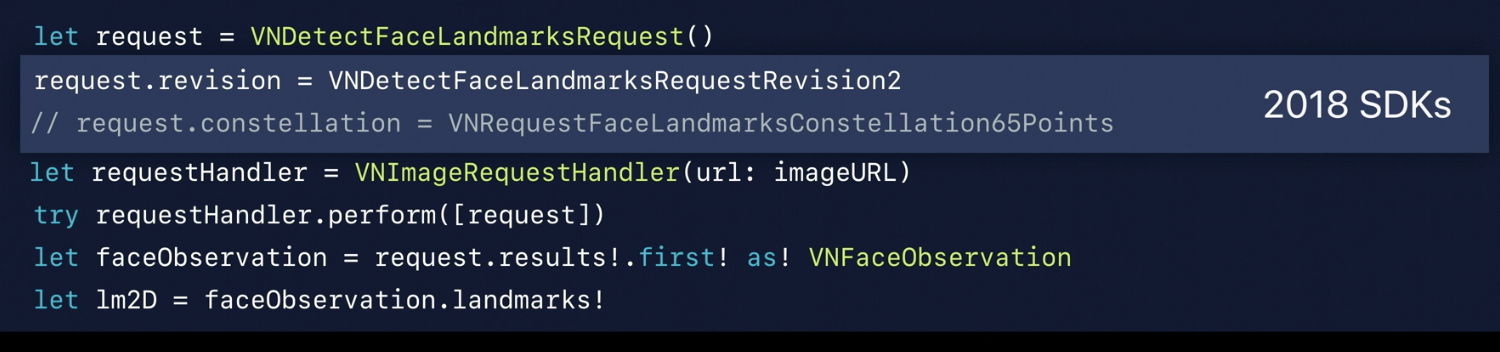
76points -> 2019 SDK
Face Capture Quality
Face Capture Quality is a holistic measure that considers: lighting, blur, occlusion, expression, pose, …

Face capture quality should not be compared against a threshold.
Face capture quality is a comparative measure of the same subject.
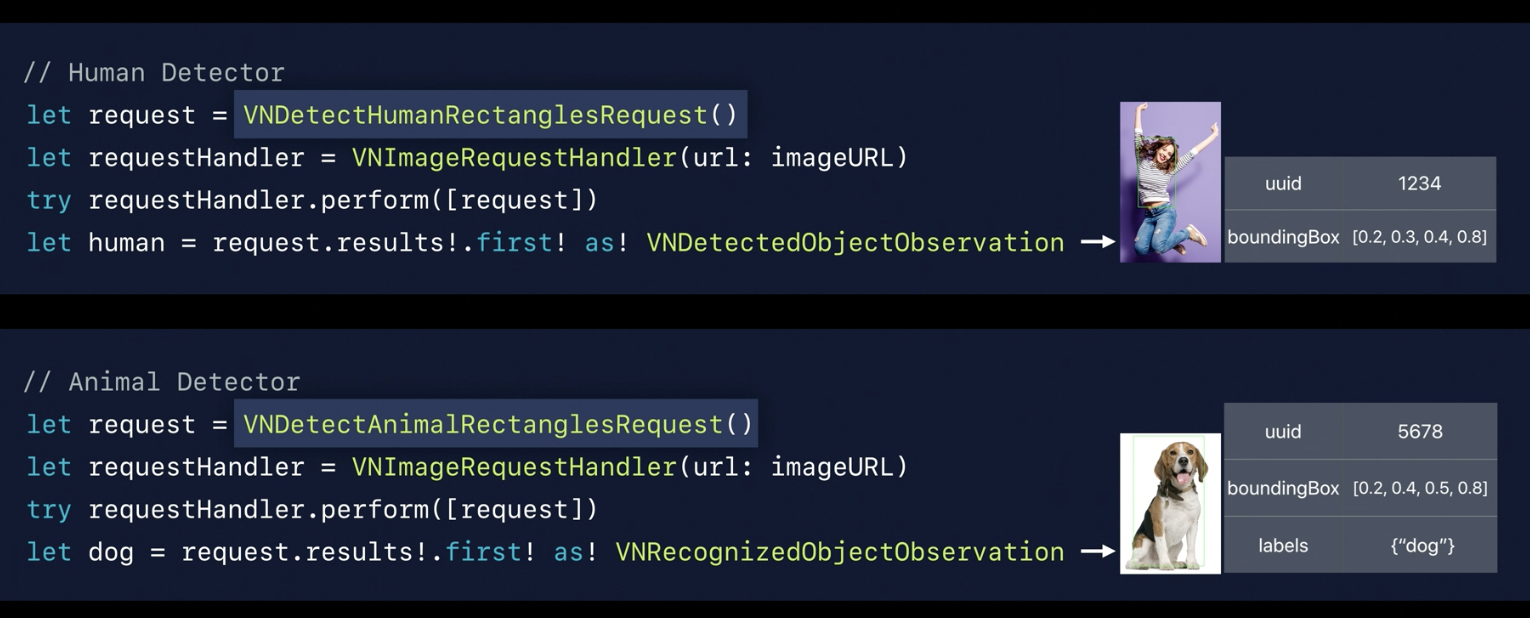
New Detector
- Human Detector
- Cat and Dog Detector
Tracking Enhancements
Less expansion into the background Better handling of occlusions Machine Learning based Runs on CPU, GPU, and A12 Bionic with low power consumption
![]()
VNSequenceRequestHandler()inputObservationcould add revision ->request.revision = VNTrackObjectRequestRevision2
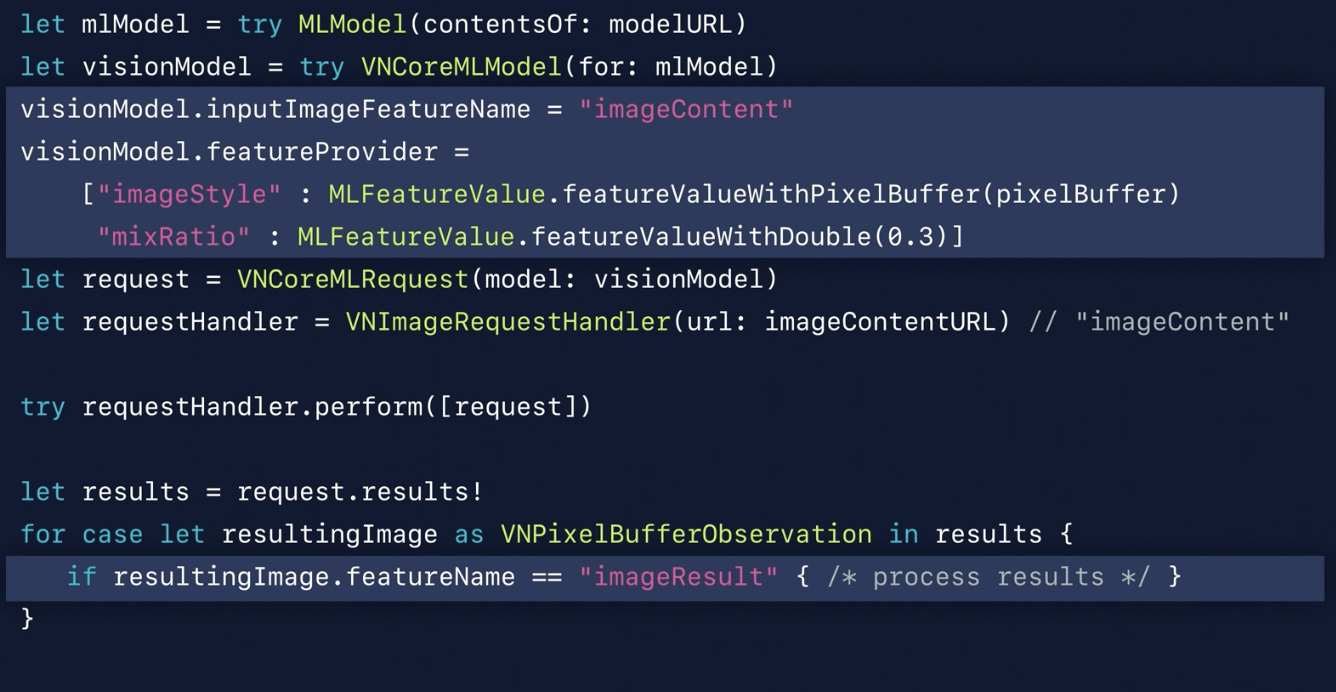
Vision and CoreML Integration Enhancements
Vision now works with CoreML models that have single input of image type
Vision converts Inputs image to CoreML required input size and color scheme
Vision wraps Outputs into appropriate Observation types
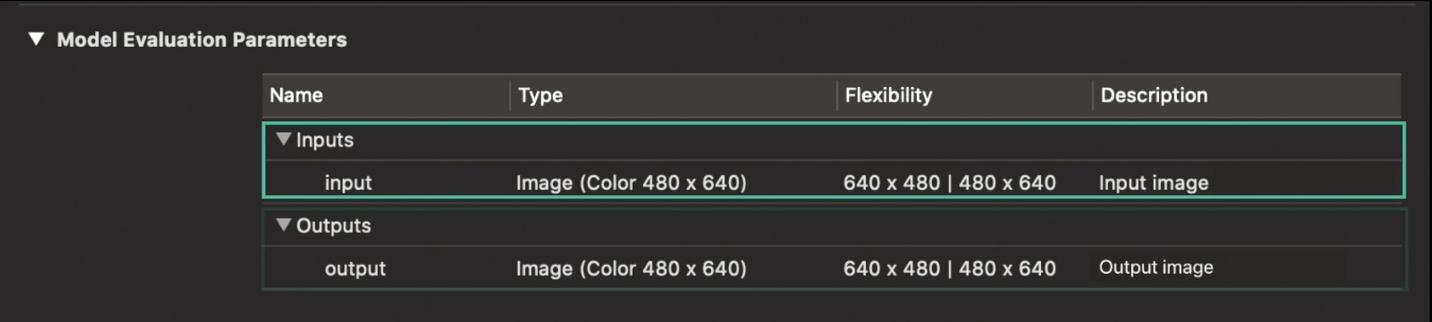
Vision can now work with CoreML models that have one or more Inputs
- Including
multi-imageinputs Vision will usename-mappingofOutputnames to Observations
Comments
Join the discussion for this article at here . Our comments is using Github Issues. All of posted comments will display at this page instantly.